Chapter 1. Overview of Penrose Virtual Directory
- 1.1. Explaining Virtual Directories
- 1.2. Looking at Penrose Virtual Directory
- 1.3. Planning Penrose Virtual Directory
- 1.3.1. Identifying Current Data Sources
- 1.3.2. Configuring a Virtual Directory through Partitions
- 1.3.3. Joining LDAP, NIS, and Active Directory Servers through Identity Federation
- 1.3.4. Synchronizing Active Directory and Other LDAP Services
- 1.3.5. Migrating from NIS Servers to LDAP Servers
- 1.3.6. Migrating to Red Hat IPA
- 1.3.7. Planning Authentication
A virtual directory creates a consolidated, high-level directory view from different sources of information. Penrose Virtual Directory is a simple and flexible way to make accessing information across a network environment easier, whether this involves a new view of LDAP and database sources, bridging between Active Directory and other LDAP servers, or performing an easier NIS migration.
This chapter provides an overview of the purpose and opportunities of using a virtual directory, the components in Penrose Virtual Directory, and considerations when planning Penrose Virtual Directory deployment.
1.1. Explaining Virtual Directories
Most organizations have a "hetergenous" network environment — meaning there is a messy combination of databases, NIS servers, Window and Unix LDAP servers which all contain important information. In heterogenous environments, these servers and applications usually cannot communicate directly with one another, or cannot communicate effectively, so the information get partitioned off into its respective server, even usernames and passwords.
Virtual directories consolidate that information without having to perform migrations, find complex software options, or try to reconfigure thousands of different entries. Virtual directories create a view or picture of a single, consolidated LDAP server and function as a type of lightweight middleware between the different servers and users. LDAP clients from email programs to servers communicate with the virtual directory. The virtual directory, in turn, talks to each server or database in its native protocol.
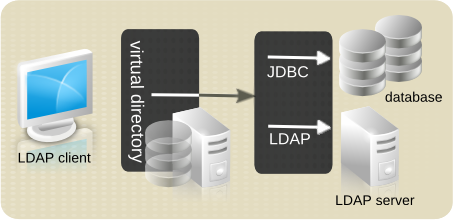
Figure 1.1. Overview of Penrose Virtual Directory
A virtual directory performs two essential functions: it provides a single source for accessing information and it creates a flattened, standardized namespace. Those two features of a virtual directory make it ideal for consolidating data in different formats from different applications.
A virtual directory is a single source because that is the only directory users need to access to get complete access to information. The virtual directory is configured to connect to each data source (without having to reconfigure the data source itself). The user or client sees the virtual directory as an LDAP directory service.
Since the virtual directory simulates an LDAP server, it has a hierarchy of subtrees and entries which correspond to actual entries in the data sources. The virtual subtrees can be named whatever the administrator wants. Even the names of the entries and the names of their attributes can be translated according to the new virtual hierarchy. Standardizing distinguished entry names is called namespace flattening.
There is an important distinction between a virtual directory and metadirectory. A virtual directory loosely couples identity data and applications; this is a real-time, dynamically-generated view, not a separate directory. A metadirectory, while also giving a consolidated view of data, adds a layer of infrastructure above native repositories. A metadirectory actually draws data out from the source and copies it into a new consolidated directory. A virtual directory is much more agile to used and configure and easier to synchronize data.
By functioning similarly to an LDAP directory, Penrose Virtual Directory has several advantages that make deploying the solution ideal:
Centralized configuration
Robust authentication
Solid integration with other applications, such as mail servers and email clients
Easily configured replication
Widely-utilized standard protocol
1.2. Looking at Penrose Virtual Directory
Penrose Virtual Directory is comprised of several components:
Penrose Virtual Directory Common, the set of classes by used all other components, including base classes, configuration classes, XML readers and writers, DTD definitions, utilities
Penrose Virtual Directory Core, the primary virtual directory component which handles partitions, source configuration, directory entries, and modules
NOTE
Penrose Virtual Directory Core can be embedded in another application without running an LDAP service.
Penrose Server, a lightweight application server which combines several different LDAP services to communicate with clients through OpenDS or ApacheDS and a JMX service to communication with Java clients
Penrose Studio, an intuitive GUI to manage Penrose Server configuration
Command-line tools and classes to manage Penrose Server remotely
Penrose Server uses Java MBeans to instantiate and manage all aspects of the virtual directory configuration, so Penrose Server can run on any platform which supports Java. Penrose Server is the primary component that users will use to create the virtual directory:
Mapping attributes and values from multiple sources into virtual entries, and converting and manipulating attribute values
Flattening the namespace and intelligently routing queries
Configurable caching
Access control information
Load-balancing and failover
Bidirectional synchronization between different LDAP servers
The Penrose Studio is a powerful yet simple tool to make managing Penrose Server easier. This provides wizards to configure partition and identitty federation entries, set up access control, and configure mapping. The Penrose Studio also includes an integrated LDAP browser to view the virtual directory and browsers to see the hierarchy of the real data sources.
1.3. Planning Penrose Virtual Directory
A virtual directory at a high level combines entries (identities), a process called identity joining, and also maps the attributes in the source to the virtual entry. Penrose Virtual Directory has several different ways that identity joining and mapping can be configured.
The following sections cover issues that should be considered while planning a virtual directory so that information and entries are effectively joined and the virtual hierarchy and configuration meet your needs.
1.3.1. Identifying Current Data Sources
Identify what sources in the infrastructure need to be consolidated.
What servers need to be joined?
Perform a survey of your complete infrastructure, across geographical locations and departments. Identify any applications or areas where the same person or identity has multiple entries; these can be joined in the virtual directory.
What tables or subtrees will supply information for the virtual directory?
Identify what parts of the infrastructure need to be included, such as the subtrees of an LDAP directory. This can also be part of auditing the information which will go into the virtual directory to help plan the virtual directory tree.
NOTE
Penrose Virtual Directory does not distinguish between virtual views in an LDAP directory or database and real subtrees and tables. Therefore, virtual views can be treated as parts of the data sources.
What protocols are used?
Penrose Virtual Directory, by default, communicates with JDBC and LDAPv3 protocols, so the server can communicate with any database or LDAPv3 compliant server, such as Red Hat Directory Server, OpenLDAP, and Active Directory. Penrose Virtual Directory can be configured to communicate to NIS servers, as well.
The protocols used for the servers can also influence the identity joining method (described in Section 1.3.2, “Configuring a Virtual Directory through Partitions” and Section 1.3.3, “Joining LDAP, NIS, and Active Directory Servers through Identity Federation”). For example, for an environment with several database applications and LDAP services, a partition virtual directory. For a NIS migration, use identity federation.
What attributes should be mapped?
Joining is configured per attribute as well as per identity, so identify what information should be included in the consolidated entry. Look for each attribute to include and what data source will supply the value.
What schema elements will be used?
Since the virtual directory is strucutred as an LDAP directory, it requires defined object classes and attributes for each kind of entry. Identify what kind of LDAP schema or custom schema elements to include.
1.3.2. Configuring a Virtual Directory through Partitions
The most common method of creating a virtual directory in Penrose Virtual Directory is through creating partitions. A partition defines virtual directory for LDAP servers and databases. Individual entries are created for each host server, application, subtree and entry, and mapped attribute. Each piece of information is defined separately:
The directory, database, or other application which contains the information (the source)
The connection information to the server machine which hosts the data source (the connection)
The hierarchy of the new, virtual directory being created (the directory)
The relationships between the entries and attributes in the different data sources (the mapping)
NOTE
The entry mapping — the way the disparate entries and attributes are combined into the virtual entries — is also configured within the partition, but this is more complex and has many different options. Entry mapping is covered in Chapter 8, Configuring the Virtual Directory.
Additional code which affects the partition behavior, such as additional mapping functionality (the module, described in Chapter 11, Configuring Modules)
These configurations, collectively, comprise the server partition entry in Penrose Server. There can be an unlimited number of partitions configured for a single Penrose Server server instance; though the default is to use a single partition. Likewise, there can be an unlimited number of sources, connections, and mappings for a single partition.
A virtual directory partition is illustrated in Figure 1.2, “A Virtual Directory Partition”.
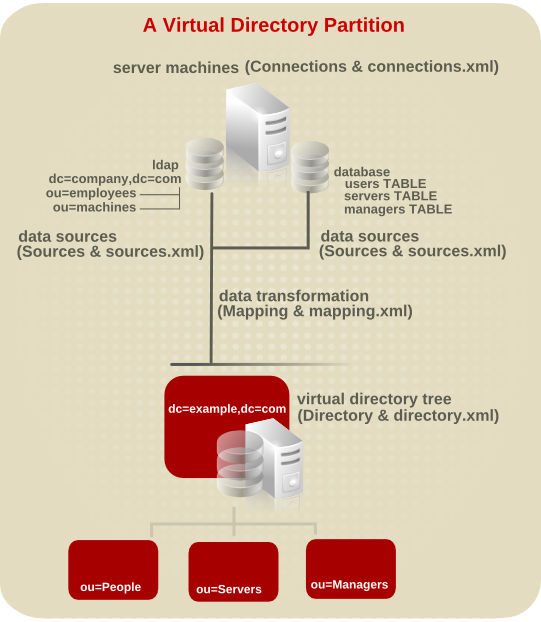
Figure 1.2. A Virtual Directory Partition
In Figure 1.2, “A Virtual Directory Partition”, each component in the partition has two areas specified, such as the connection having both connections.xml and Connection. All of the Penrose Server partition components are defined in XML files, which can be edited directly. These components can also be configured through Penrose Studio, as shown in Figure 1.3, “Partition Configuration in Penrose Studio”. For a connection, then, connections.xml is the configuration file and Connection is the folder in the Penrose Studio hierarchy for changes.
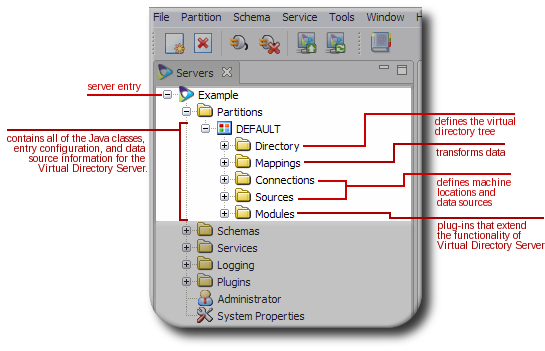
Figure 1.3. Partition Configuration in Penrose Studio
1.3.3. Joining LDAP, NIS, and Active Directory Servers through Identity Federation
Identity federation or identity linking is a method to unite entries from Active Directory, LDAPv3, or NIS servers. This method can be used to synchronize these types of servers or to simplify a NIS migration.
Identity federation, like partition directories, takes source entries to create a virtual directory entry, but is for different source environments.
Identity linking (or federation) creates a hybrid virtual directory and meta directory by using a global repository to combine and synchronize entries from the different sources. Local repositories (analogous to sources in the virtual directory configuration) are linked to the global repository. Using a mapping tool, the local identities are then matched to entries in the global repository.
With identity federation, there is a global repository, a separate and authoritative source for entries. In this figure, a NIS source is used to create the initial global entry. After that global repository is defined, entries from other sources (local repositories) are linked to the global entry either manually or through matching rules.
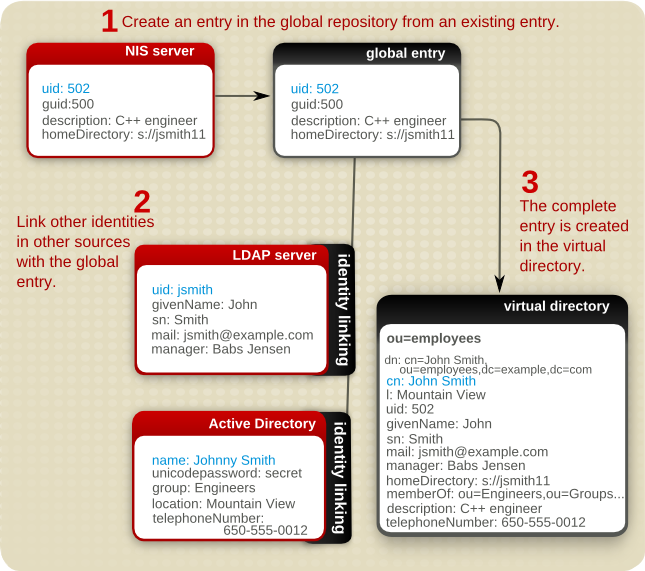
Figure 1.4. Merging Entries through Identity Linking
1.3.4. Synchronizing Active Directory and Other LDAP Services
Active Directory and other LDAPv3 compliant directory services cannot communicate or synchronize data easily. Some directory services have tools which try to bridge the differences in schema, entry naming, and directory hiearchy, such as Windows Sync in Red Hat Directory Server. However, these tools are usually limited to a small subset of entry attributes (without any support for custom or non-standard attributes) and have restrictions on the kinds of entries and locations in the subtrees where sycnhronization can occur.
Penrose Virtual Directory aids synchronization between Active Directory and LDAPv3 compliant directory services, including support for all Active Directory schema and custom schema.
Active Directory and LDAP synchronization can be configured through a partition or through identity federation; the method does not really matter. The key is in mapping the attributes between the Active Directory and LDAP servers.
The synchronization with Penrose Virtual Directory will check activity on one server and then write those changes over to the other server. There are two ways that Penrose Virtual Directory keeps track of changes:
A full synchronization, which periodically takes snapshots of one server, compares it to the data on the target server, and writes over any changes.
An incremental update, which uses a change log to track and copy over changes to the target server.
This method can also be used to synchronize other LDAPv3 servers which normally cannot be synchronized, such as OpenLDAP and Red Hat Directory Server, using identity federation.
1.3.5. Migrating from NIS Servers to LDAP Servers
Penrose Virtual Directory simplifies NIS server migrations to LDAP, without interrupting the NIS service and remaining transparent to users.
Penrose Virtual Directory uses a lazy migration process, there there are two views of the data, one in the old location and one in the new location. In Penrose Virtual Directory, the old NIS location is a local repository. All of the NIS entries are migrated over to a new LDAP server, called a global repository. This migration can take several weeks, with a mix of entries in the old and new data formats. Al entries will be available in the new data source.
At any point in the migration process, data can be accessed on either the old or new repositories.
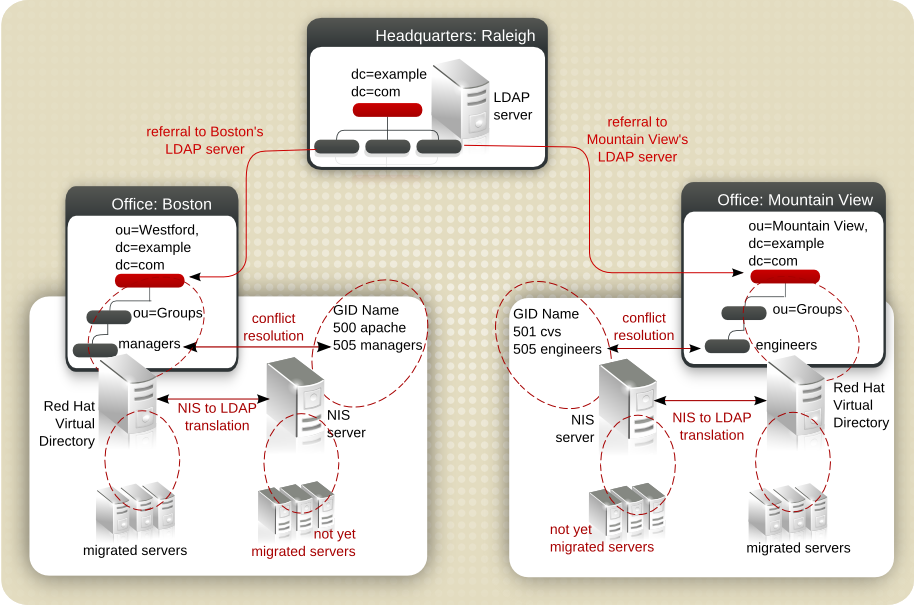
Figure 1.5. Example of a NIS to LDAP Migration
A lazy migration is much simpler than trying to force a reconfiguration of all applications at the same time. Applications and clients can be switched over incrementally. This also eliminates almost all of the downtime of the migration, since the switchover takes just a few seconds. There is no need to cram a migration into a rigid outage window.
Penrose Virtual Directory supplies several tools which make is easy to match entries between NIS and LDAP repositories and to resolve UID and GID conflicts, including reassigning file ownerships. The NIS migration process using Penrose Virtual Directory is as follows:
Copy the information in the NIS servers to a central directory server, a global repository.
Configure the global repository subtrees to contain three branches:
Create a subtree for the current NIS servers, such as
ou=nis. This will be mapped to the current, old NIS server entries.Create a subtree for the new global repository, such as
ou=global. This is mapped to the new global LDAP repository; any new entries are written to the global repository, and any changes write the NIS entries over to the global repository.Create a subtree for users to access, such as
ou=nss. Before the migration begins,ou=nsshas a referral to the NIS subtree,ou=nis. After the NIS migration begins, this has a referral to the global repository subtree,ou=global.
Link the identities in the NIS server to entries in the global repository.
If there are multiple NIS servers, then the same unique ID number many have been assigned to more than one user. These UID, as well as group ID, conflicts can be resolved using Penrose Virtual Directory's UID/GID Conflict Resolution tool.
After any UID/GID conflicts are resolved, new UIDs will be reassigned. After reassigning UIDs, then the file ownership for any files associated with that UID or GID must also be reassigned. This is done using the Ownership Alignment Tool.
The migration of entries begins. Any changes to the NIS entries are written over to the global repository.
As the migration for a server is completed, change the PAM modules on the NIS server hosts to point to the global repository rather than the NIS server.
Switch from performing operations against the NIS server (
ou=nis) to running against the global LDAP repository (ou=global). Users have always performed operations againstou=nss, so change the referral for that subtree fromou=nistoou=global.
1.3.6. Migrating to Red Hat IPA
Many applications do not have a native migration path to more advanced servers; Penrose Virtual Directory can fill in the gap for migration and allow NIS servers and LDAP servers to migrate to Red Hat IPA. This migration is even possible for LDAP servers in a Kerberos/SASL environment, which would otherwise be trickier to manage.
As with a NIS to LDAP migration, Penrose Virtual Directory can use a lazy migration to allow migration to happen incrementally by supply two different resources, the original source and the new IPA source, and working as a pass-through application. Penrose Virtual Directory also resolves entry, UID number, group ID number, and file ownership conflicts through its toolset.
The process for migrating to Red Hat IPA is very similar to migrating to NIS to LDAP, and as in that migration, this uses identity federation to unify and resolve entries, as shown in Figure 1.4, “Merging Entries through Identity Linking”:
Copy the initial entry information into Red Hat IPA, and set up Red Hat IPA as the global repository.
Configure the global repository subtrees to contain three branches: one for the current server (for example,
ou=ldap), one for the IPA server (for example,ou=ipa), and one to which to point clients (for example,ou=federation). Having a third subtree makes the process easier on clients; they simply access that subtree at any point in the migration. Theou=federationsubtree contains a referral to the appropriate source. Before migration, this referral directs to the original source,ou=ldap, and after migration, it points to the IPA subtree,ou=ipa. The referral can be changed without affecting users.Link the identities in the old NIS or LDAP server to entries in the IPA global repository.
Resolve any conflicts. If there are multiple servers being migrated, more than one entry may have the same user or group ID. Two tools helps resolve the UID/GID conflicts and then align the file ownership with the new UID numbers.
Begin migrating entries, clients, and applications.
When migration is complete, switch from performing operations against the old server subtree (
ou=ldap) to running against the global IPA repository (ou=ipa). Users have always performed operations againstou=global, so change the referral for that subtree fromou=ldaptoou=ipa.
Using Penrose Virtual Directory to assist with the incremental migration to IPA has several benefits:
Synchronized data between old servers and new IPA servers.
Integrated tools to reconcile UID conflicts and to simplify federating entries.
No lost time or outage windows to coordinate simultaneous migrations.
Transparent to users.
Extensible support for legacy schema which may be required or hardcoded in legacy applications; by using Penrose Virtual Directory as a proxy, these legacy applications can communicate with IPA.
Synchronization between IPA and other applications, such as Active Directory.
1.3.7. Planning Authentication
The most common reason administrators want a virtual directory is to provide LDAP-style uathentication to databases or to provide a single sign on service when a user has multiple logins.
Penrose Virtual Directory can perform simple authentication through both partition-style hierarchies and identity federation. Identity federation, with the different relationship established between repositiories, also can be configured for stacking authentication. Stacking authentication can verify a user's credentials against several repositories in a single operation. A user's credentials are first presented to the global repository, then cascades down all of the configured local repositories.
For example, a user attempts to bind to a Red Hat Directory Server instance through Penrose Virtual Directory with the following command:
ldapsearch -h rhvd.example.com -p 10389 -D uid=jsmith,ou=users,ou=nisdomain,ou=nss,dc=example,dc=com -w secret -x -b "" -s subtree
The authentication operation proceeds as follows:
Penrose Virtual Directory searches the local repository for a user with the
uidjsmith.If the local entry is found in the local repository, then Penrose Virtual Directory searches the global repository for an entry which contains a link to the local entry, meaning an entry with a
seeAlsoattribute which contains the local entry DN.If there is a global entry, Penrose Virtual Directory checks the other entries contained in the
seeAlsoattribute for any account disable, account lockout, or account expiration attributes.If the account is still active, then Penrose Server checks the global identity for a
userPasswordattribute.Penrose Server uses the local identity's
uidand global identtity'suserPasswordto bind to the specified Red Hat Directory Server.
TIP
Stacking authentication is ideal for NIS migration because it allows users to authenticate against a virtual NSS subtree, and that authentication is then performed against all of the federated NIS identities.